Hark back to the 'sample data' postings and use COPY amd_bang_per_watt FROM ... if you are coming to this fresh.
I will deal with 'xml out' first as it is a quick win for an already populated table (my situation)
Previous postings have been quite console - this one will be a bit more gui so as to allow us to explore features of the pgAdmin graphical tool.
There are several ways including:
- Using psql with the html flag and then munging the html into xml
- pgAdmin's table view, clicking 'context menu', and outputting with xml radio button
- pgAdmin 'Tools/Query Tool' then 'File/Quick report' (xml radio button selected)
(Item 3 gave me the best results so feel free to skip ahead if you like)
My pgAdmin screenshots are wide and will not resize well for newspaper style columns. Instead I have put them on picasaweb with links in the text.
2. Tools/Query Tool then File/Quick report:
- Table view within pgAdmin
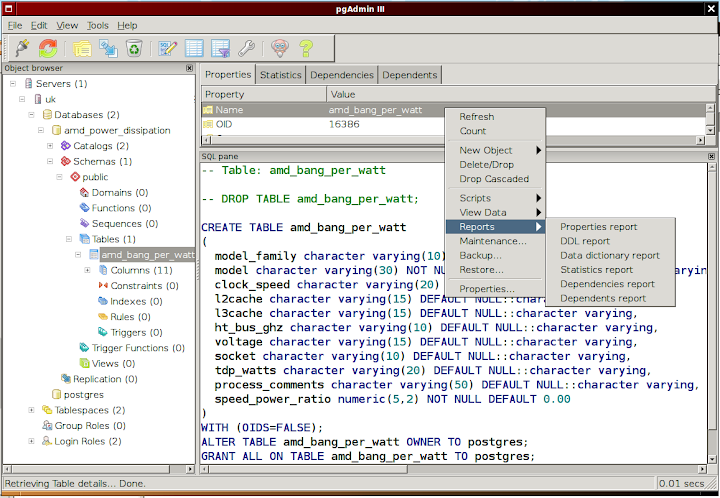
- Context menu from Table view within pgAdmin
{kind=link}
{kind=link}
- Properties report (an extract is shown below)
- DDL report (ddl for table recreation from a script)
- Data Dictionary report (an accurate description of what you get)
- Statistics Report (Sequential scans count is expectedly high in here)
- Dependencies Report (for our table this is empty in an xml style of emptiness)
- Dependents Report (whoops - incorrect spellcheck complaint in firefox)
<table>
<columns>
<column id="c1" number="1" name="Property" />
<column id="c2" number="2" name="Value" />
</columns>
<rows>
<row id="r1" number="1" c1="Name" c2="amd_bang_per_watt" />
<row id="r2" number="2" c1="OID" c2="16386" />
<row id="r3" number="3" c1="Owner" c2="postgres" />
<row id="r4" number="4" c1="Tablespace" c2="pg_default" />
<row id="r5" number="5" c1="ACL" c2="{postgres=arwdxt/postgres,someuser=arwd/postgres}" />
<row id="r6" number="6" c1="Primary key" c2="" />
<row id="r7" number="7" c1="Rows (estimated)" c2="50" />
<row id="r8" number="8" c1="Fill factor" c2="" />
<row id="r9" number="9" c1="Rows (counted)" c2="50" />
<row id="r10" number="10" c1="Inherits tables" c2="No" />
<row id="r11" number="11" c1="Inherited tables count" c2="0" />
<row id="r12" number="12" c1="Has OIDs?" c2="No" />
<row id="r13" number="13" c1="System table?" c2="No" />
<row id="r14" number="14" c1="Comment" c2="" />
</rows>
</table>
Click the links in the original six point list for googledocs of all the xml files in full.
What I did not find in any of the six reports was the actual row data from the table - will come to that soon.
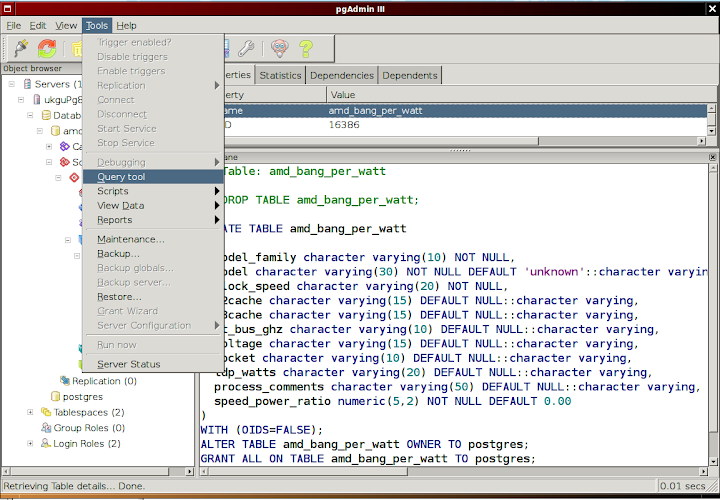
3. Tools/Query Tool then File/Quick report:
My pgAdmin screenshots are wide and will not resize well. Instead I have put them on picasaweb with links listed below:
- Tools/Query Tool
- Query Tool example query
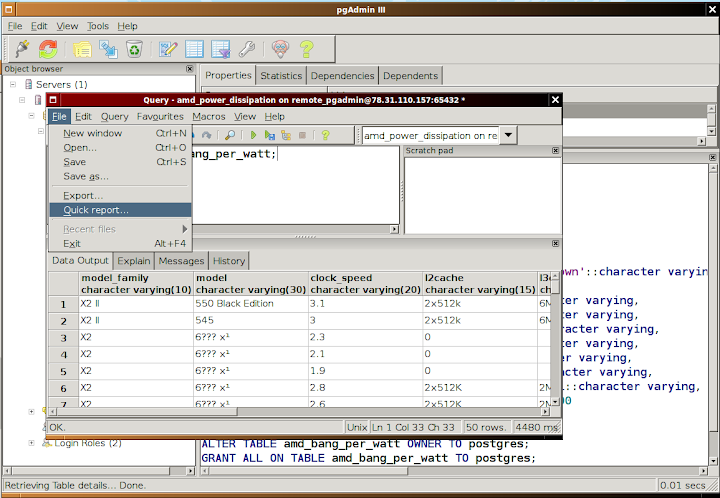
- Query Tool 'File/Quick Report' *** bingo ***
{kind=link}
{kind=link}
{kind=link}
Having selected XML in Quick Report you will obtain the actual row data from the table.
Does this row data look the same as mysql --xml style output?
Not exactly. What happens in pgAdmin xml output is that columns are not treated as individual nodes but instead are attributes of a row node.
Sample first row from the full xml output:
<row id="r1" number="1" c1="X2 II " c2="550 Black Edition " c3="3.1" c4="2x512k " c5="6MB " c6="2" c7="1.15-1.425 " c8="AM3 " c9="80" c10="45nm Callisto Q3-2009 " c11="38.75" />
Is this a valid way of representing xml? Certainly.
Will it lead to parsing issues? - No. Any parser worth its salt handles nodes and attributes and exposes them in a useful way to the programmer.
Perhaps you might later use python-libxml2 or similar to construct an insert statement of the form INSERT INTO amd_bang_per_watt VALUES(_,_, from the column entries c1,c2,etc.
This 'more compact' format should save you space and may be doing you a favour if you harbour any thoughts of parsing the rows in jQuery or PHP.
One thing I should point out is that this compact form comes at a price. Should you later insert or remove columns from the table, then the column numbers c1, c2, c3, etc are going to be out of step with your altered table.
The facilities for xml output in your database can be useful, but are not always the quickest route to goal. If you data is going out, then into another postgres database then you would likely want to use the backup option in pgAdmin.
Example of such backup output are shown below:
- Familiar 'one insert per line' form that this human finds easy to look at.
- Postgres compact form
xml in xml out (part 2 of 3) is the next post and will continue this theme.
No comments:
Post a Comment